
Tuesday, December 3, 2024
You may have heard that Google Search needs to do a bit of work before a web page can show up in
Google Search results. One of these steps is called crawling. Crawling for Google Search is done
by Googlebot, a program running on Google servers that retrieves a URL and handles things like
network errors, redirects, and other small complications that it might encounter as it works its
way through the web. But there are a few details that aren’t often talked about. Each week this
month we’re going to explore some of those details as they may have a significant effect on how
your sites are crawled.
Backing up a little: What is crawling?
Crawling is the process of
discovering new and revisiting updated web pages, and downloading them. In short, Googlebot gets
a URL, makes an HTTP request to the server hosting it and then deals with the response from that
server, possibly following redirects, handling errors, and passing the page content on to
Google’s indexing system.
But modern web pages aren’t just pure HTML, so what about the other resources that make up a page?
How does crawling these resources affect “crawl budget”? Are these resources cacheable on Google’s
side? And is there a difference between URLs that have not been crawled before and those that are
already indexed? In this post we’re going to answer these questions, and more!
Googlebot and crawling page resources
Beyond HTML, modern websites use a combination of different technologies such as JavaScript and
CSS to offer users vibrant experiences and useful functionalities. When accessing such pages with
a browser, the browser first downloads the parent URL which hosts the data needed to start
building the page for the user — the HTML of the page. This initial data may contain
references to resources like JavaScript and CSS, but also images and videos that the browser will
once again download to eventually construct the final page which is then presented to the user.
Google does exactly the same thing,
though slightly differently:
- Googlebot downloads the initial data from the parent URL — the HTML of the page.
- Googlebot passes on the fetched data to the Web Rendering Service (WRS).
- Using Googlebot, WRS downloads the resources referenced in the original data.
- WRS constructs the page using all the downloaded resources as a user’s browser would.
Compared to a browser, the time between each step may be significantly longer due to scheduling
constraints such as the perceived load of the server hosting the resources needed for rendering a
page. And this is where
crawl budget
slips into the conversation.
Crawling the resources needed to render a page will chip away from the crawl budget of the
hostname that’s hosting the resource. To ameliorate this, WRS attempts to cache every resource
(JavaScript and CSS) referenced in pages it renders. The time to live of the WRS cache is
unaffected by HTTP caching directives; instead WRS caches everything for up to 30 days, which
helps preserve the site’s crawl budget for other crawl tasks.
From the site owners’ perspective, managing how and what resources are crawled can influence the
site’s crawl budget; we recommend:
-
Use as few resources as feasible to offer users a great experience; the fewer
resources are needed for rendering a page, the less crawl budget is spent during rendering. -
Host resources on a different hostname from the main site, for example by
employing a CDN or just hosting the resources on a different subdomain. This will shift crawl
budget concerns to the host that’s serving the resources. -
Use cache-busting parameters cautiously: if the URLs of resources change,
Google may need to crawl the resources again, even if their contents haven’t changed. This, of
course, will consume crawl budget.
All these points apply to media resources, too. If Googlebot (or more specifically,
Googlebot-Image and Googlebot-Video respectively) fetches them, it will
consume the crawl budget of the site.
It is tempting to add robots.txt to the
list also, however from a rendering perspective disallowing crawling of resources usually causes
issues. If WRS cannot fetch a rendering-critical resource, Google Search may have trouble
extracting content of the page and allowing the page to rank in Search.
What is Googlebot crawling?
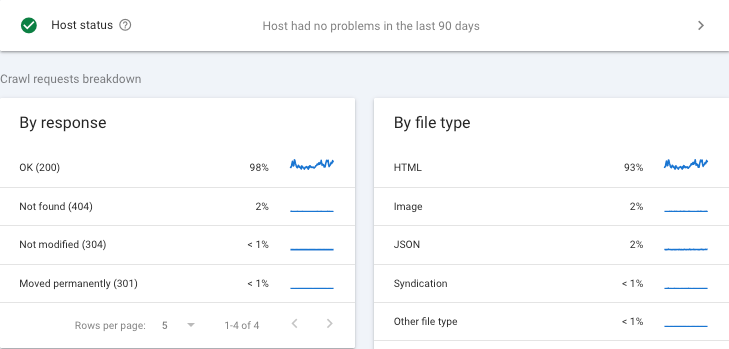
The best source to analyze what resources Google is crawling is the site’s raw access logs which
has an entry for every URL that was requested by browsers and crawlers alike. To identify Google’s
crawlers in the access log, we publish our
IP ranges in our developer documentation.
The second best resource is, of course, the
Search Console Crawl Stats report,
which breaks out each kind of resource per crawler:

Finally, if you are really into crawling and rendering and wanna chat about it with others, the
Search Central community is the place
to go, but you can also find us on
LinkedIn.